
Pixcavator Image Search 1.1
This has been an on-and-off project for almost two years (version 1.0 described here). The purpose is simple: find images similar to a given image. Since it is not even well understood what images are similar, the progress in this area of “image-to-image” search (aka “visual image search”) is very slow-. So, instead, we focus on the goal of finding modified versions of the original. This release is a way to report a limited success we have achieved.The executable PxSearch.exe is accompanied by a small collection of images (download here, 7.2 MB). The system consists of the following modules:
- the collection of images that can be extended;
- the database containing “signatures” of images, images’ origins, and other data;
- the image analysis unit (produces the signatures);
- the matching unit (matches the signatures);
- user interface (uploads an image, searches for similar images in the collection, displays the matches as a list);
For every image to be added, first the image is converted to grayscale and then shrunk so that the larger dimension is 150. Then several of its secondary versions are created, analyzed, and added to the collection and their data is added to the database, total of 8:
- original
- rotation, 5 degrees
- rotation, 45 degrees
- Gaussian blur
- salt and pepper noise
- stretch, 5%
- shrink, 5%
- crop from all sides, 5%
The entry in the database for each image contains the information about its origin:
- date and time,
- the filename of the original image,
- the way the image was produced from the original (shrinking, rotation, etc),
- the signature of the image.
A signature is a sequence of 126 integers which is the output of image analysis: it is essentially the distribution of sizes of objects found in the image (the data comes form the same source as for Pixcavator).
Suppose the signature of the two images are {An} and {Bn}. Move along these sequences and compute the absolute value of the differences of n-th entries. The result is a distance formula as the “weighted 1-norm metric”:
D = Σ Cn |An - Bn|.
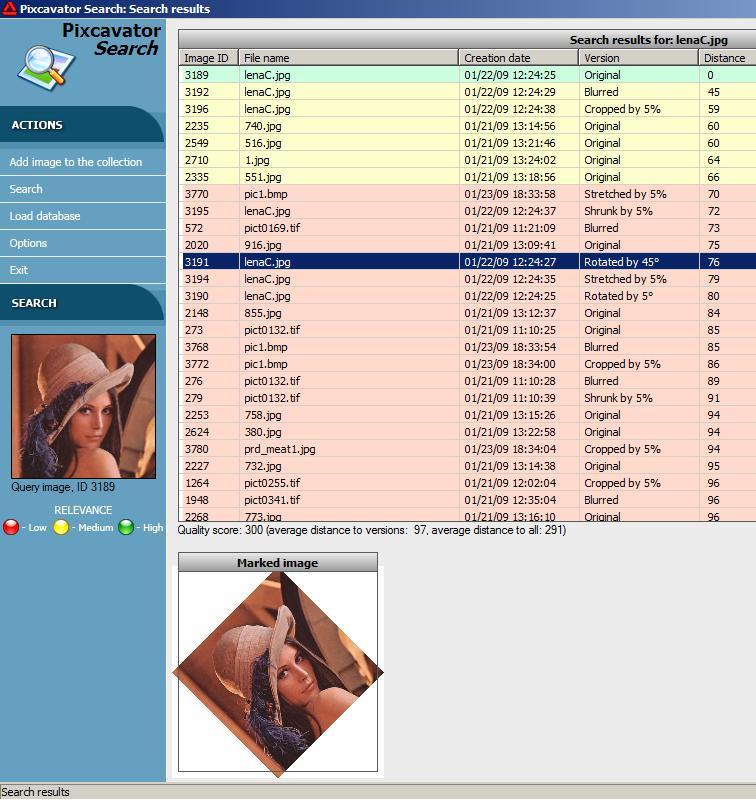
A search is deemed successful if most of the versions of the query image are at the top of the list. This is the case for images that are “good” in the sense that they have clear pattern (based on shapes not color). However, this standard is hard to quantify as it is dependent on the collection. Since the collection I used for testing was small (4500 images), I had to find a way to evaluate the quality of searches that is independent of the size of the collection, as much as possible. So, the quality score for a given image was
(average distance to its 7 versions) / (average distance to all images) * 100.
There are many interesting question to study based on this data and I will report further.
Digital discoveries
- Casinos Not On Gamstop
- Non Gamstop Casinos
- Casino Not On Gamstop
- Casino Not On Gamstop
- Non Gamstop Casinos UK
- Casino Sites Not On Gamstop
- Siti Non Aams
- Casino Online Non Aams
- Non Gamstop Casinos UK
- UK Casino Not On Gamstop
- Non Gamstop Casino UK
- UK Casinos Not On Gamstop
- UK Casino Not On Gamstop
- Non Gamstop Casino UK
- Non Gamstop Casinos
- Non Gamstop Casino Sites UK
- Best Non Gamstop Casinos
- Casino Sites Not On Gamstop
- Casino En Ligne Fiable
- UK Online Casinos Not On Gamstop
- Online Betting Sites UK
- Meilleur Site Casino En Ligne
- Migliori Casino Non Aams
- Best Non Gamstop Casino
- Crypto Casinos
- Casino En Ligne Belgique Liste
- Meilleur Site Casino En Ligne Belgique
- Bookmaker Non Aams
- カジノ ライブ
- онлайн казино с хорошей отдачей
- スマホ カジノ 稼ぐ
- ブック メーカー オッズ
- Top 3 Nhà Cái Uy Tín Nhất
- Trang Web Cá độ Bóng đá Của Việt Nam
- Casino En Ligne Avis
- Casino En Ligne France
- Casino En Ligne
- 꽁머니 토토
- Casino Online Non Aams
- Migliori Casino Non AAMS
- Meilleur Casino En Ligne
- Casino En Ligne France Légal
- Casino En Ligne France Légal
- Casinos En Ligne
- Mejores Casinos Online




