This page is a part of CVprimer.com, a wiki devoted to computer vision. It focuses on low level computer vision, digital image analysis, and applications. It is designed as an online textbook but the exposition is informal. It geared towards software developers, especially beginners, and CS students. The wiki contains mathematics, algorithms, code examples, source code, compiled software, and some discussion. If you have any questions or suggestions, please contact me directly.
Image-to-image search
From Computer Vision Primer
... as opposed to text-to-text and text-to-image we are familiar with.
In this article we will review some attempts to create a visual image search engine. The main interest is in is the image search technology that is independent of color (and of course independent of tags). In some areas, such as radiology, all images are gray scale.
See also our blog Computer Vision for Dummies.


CBIR = Content based image retrieval
CBIR is based on collecting "descriptors" (texture, color histogram, etc) from the image and then looking for images with similar descriptors.
The question is, This can work but what would guarantee that it will? More narrowly, what information about the image should be passed to the computer to ensure that the computer will succeed in finding good matches?
Option 1: we pass all information. Then, this could work. For example, the computer represents every 100x100 image a point in the 10,000-dimensional space and then runs clustering. First, this may be impractical and, second,.. does it really work? Will the one-object images form a cluster? Or maybe a hyperplane? One thing is clear, these images will be very close to the rest because the difference between one object and two may be just a single pixel.
Option 2: we pass some information. What if you pass information that cannot possibly help to classify the images the way we want? For example, you may pass just the value of the (1,1) pixel, or the number of 1’s, or 0’, or their proportion. Who will make sure that the relevant information (adjacency) isn’t left out? Computer doesn’t know what is relevant – it’s hasn’t learned “yet”. If it’s the human, then he would have to solve the problem first, if not algorithmically then at least mathematically.
Thus, CBIR shares some of the problems of machine learning.
Conclusions:
- Visual image search engines (below) exist only as experimental prototypes (demos, toys, etc). Worse yet, many make broad claims with nothing to back them up. If you have the technology, how hard is it to create a little web based demo!
- Most demos work with small collections of images, with no upload feature, which makes testing impossible.
- When testing is possible, the results are questionable.
- The only well developed approaches are based on the distribution of colors, texture, and image segmentation.
- In the image search context, Fourier transform and wavelet transform have been mostly used for image compression.
- The engines provide only “likeness” search, which is very subjective and obscures the fact the image analysis methods are inadequate.
- “User feedback”, “learning”, and “semantic” features obscure the fact the image analysis methods are inadequate.
Will the image analysis methods become adequate for CBIR any time soon?
Pixcavator image search (PxSearch)
The distribution of sizes of objects can be used in image search. I other words we match images based on their busyness.
The analysis follows our algorithm for Grayscale Images. The count of objects is not significantly affected by rotations. The output for the original 640×480 fingerprint in this image is 3121 dark and 1635 light objects. For the rotated version, it is 2969-1617. By considering only objects with area above 50 pixels, the results are improved to 265-125 and 259-124, respectively.
Stretching the image does not affect the number of objects. The distribution of objects with respect to area is affected but in an entirely predictable way. Shrinking makes objects merge. If the goal, however, is to count and analyze large features, limited shrinking of the image does not affect the outcome. The counting is also stable under “salt-and-pepper” noise or mild blurring. This is not surprising. After all, what the algorithm is designed to compute corresponds to human perception. The only case when there is a mismatch is when the size, or the contrast of the object, or its connection to another object are imperceptible to the human eye.
See also Industrial quality inspection.
PxSearch searches within your collection of images for pictures similar to the one that you choose. The program is available upon request. A web application is under development.
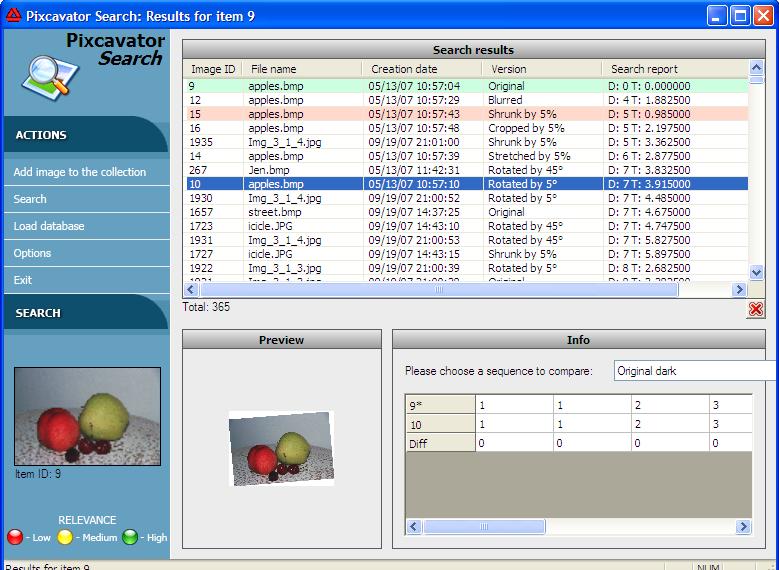
This test program adds an image to the collection, along with a few of its versions (rotated, blurred, etc). The total of 8 images are analyzed for each image you add to the collection. This feature is needed to help you see when the algorithm works well and when it does not. The idea is that these versions of the image have to appear near the top when you search for similar images. The appropriate image have to be of good quality, with several larger objects, little pixelation, noise etc. Faces, simple landscapes, some medical images work. Fingerprints don't. But I think many would work if the thumbnails were larger. Computation isn’t fast in the first place and then analyzing extra 7 versions of the image takes extra time. So, I had to shrink the images to 100x100 to make the processing time reasonable.
PxSearch computes distributions of objects of each size. Those are called "signatures". The matching is also very simple. To match two images, their signatures are compared by means of the weighted sum of differences. The end result is that the images are matched based on a quantifiable similarity. In particular, copies of the image are found even iof they are distorted etc. A good application could be in copyright filtering [1].
The main difference from some common approaches to image matching is that Pixcavator Search takes into account some global features (see a remark on local vs. global here).
cellAnalyst can also be thought of as a visual image search engine. The difference is that its search however is based on concrete data collected from the image: cells quantity, sizes, shapes, and locations. As a result it does not share CBIR problems.
For numerous examples, see Visual image search engines.
See also Other software projects.
Digital discoveries
- Casinos Not On Gamstop
- Non Gamstop Casinos
- Casino Not On Gamstop
- Casino Not On Gamstop
- Non Gamstop Casinos UK
- Casino Sites Not On Gamstop
- Siti Non Aams
- Casino Online Non Aams
- Non Gamstop Casinos UK
- UK Casino Not On Gamstop
- Non Gamstop Casino UK
- UK Casinos Not On Gamstop
- UK Casino Not On Gamstop
- Non Gamstop Casino UK
- Non Gamstop Casinos
- Non Gamstop Casino Sites UK
- Best Non Gamstop Casinos
- Casino Sites Not On Gamstop
- Casino En Ligne Fiable
- UK Online Casinos Not On Gamstop
- Online Betting Sites UK
- Meilleur Site Casino En Ligne
- Migliori Casino Non Aams
- Best Non Gamstop Casino
- Crypto Casinos
- Casino En Ligne Belgique Liste
- Meilleur Site Casino En Ligne Belgique
- Bookmaker Non Aams
- カジノ ライブ
- онлайн казино с хорошей отдачей
- スマホ カジノ 稼ぐ
- ブック メーカー オッズ
- Top 3 Nhà Cái Uy Tín Nhất
- Trang Web Cá độ Bóng đá Của Việt Nam
- Casino En Ligne Avis
- Casino En Ligne France
- Casino En Ligne
- 꽁머니 토토
- Casino Online Non Aams
- Migliori Casino Non AAMS
- Meilleur Casino En Ligne
- Casino En Ligne France Légal
- Casino En Ligne France Légal
- Casinos En Ligne
- Mejores Casinos Online
