





ImageJ vs. Pixcavator
Here we compare the capabilities of ImageJ (without plug-ins) and Pixcavator 2.4 in analysis of gray scale images. The links will take you to the relevant articles in the wiki. Update: The list is addressed mostly to the users. For the developers, there will be a similar list comparing ImageJ (including plug-ins) and Pixcavator SDK.
|
Tasks and features |
ImageJ |
Pixcavator |
|
Analysis of the gray scale image after binarization |
Yes |
Yes |
|
Computation of binary characteristics of objects/particles |
Yes (A specific binarization has to be found first by thresholding or another method.) |
(The characteristics are computed for all possible thresholds.) |
|
size/area |
Yes |
|
|
circularity/roundness |
Yes |
|
|
centroid |
Yes |
Yes |
|
perimeter |
Yes |
Yes |
|
bounding rectangle |
Yes |
No (Useless for such applications as microscopy where the results should be independent of orientation) |
|
|
|
|
|
Analysis of the gray scale image without prior binarization |
Limited |
|
|
Detection of objects as max/min of the gray scale |
Yes |
|
|
Filtering detected objects (in order to deal with noise etc) |
Yes (with respect to contrast only) |
Yes (with respect area, contrast, roundness, and saliency) |
|
Counting objects/particles |
Yes |
|
|
Image segmentation method |
Watershed - for either max or min but not both (dark or light objects but not both) |
Topology (both dark and light objects) |
|
Computation of gray scale characteristics of objects |
No |
|
|
contrast |
No |
|
|
center of mass |
No |
Yes |
|
saliency/mass |
No |
|
|
average contrast |
No |
Yes |
|
|
|
|
|
Automatic analysis |
Yes |
Yes |
|
Semi-automatic mode |
No |
Yes (based on objects found for all possible thresholds) |
|
Manual mode |
No |
Yes (full control over found objects) |
|
User interface |
Hundreds of commands in drop down menus |
4 sliders, 7 buttons |
|
User experience (mine) |
“Wrong image format!” “Threshold first!” “Results unsatisfactory? Start over!” |
|
|
Screenshots |
|
|
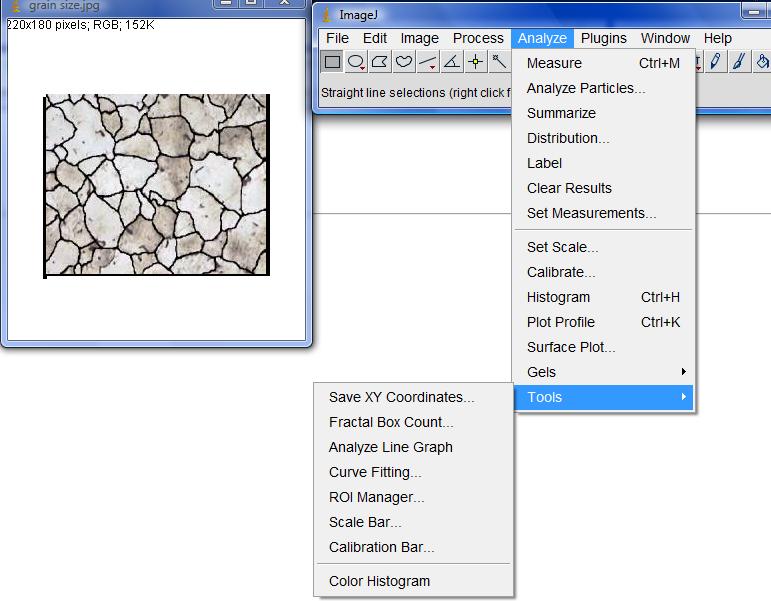
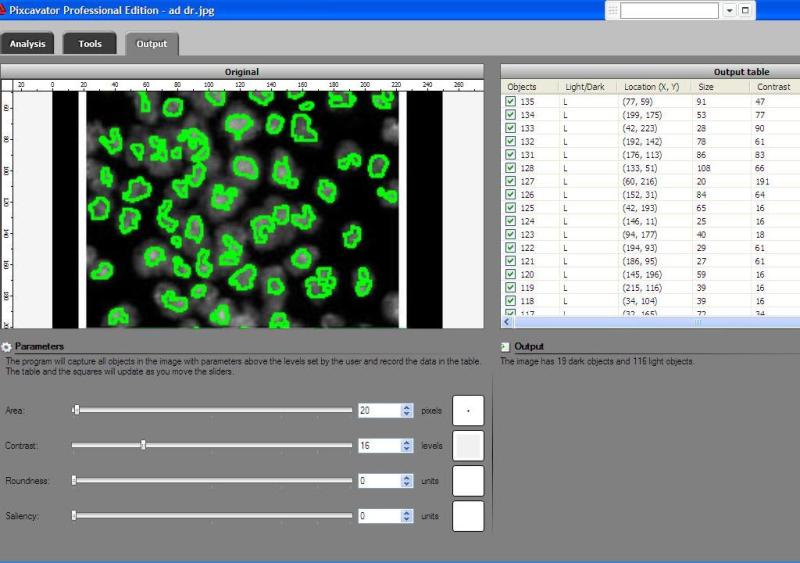
Update: The main criticism has been that some positive things about ImageJ are missing from the table. They are added below (not about image analysis but still). On the other hand, none of the statements in the above part has been questioned.
| Platforms |
Windows, Mac, Linux |
Windows only (cellAnalyst web application soon to come) |
| Price |
Free |
$150 (free trial) |
Digital discoveries
- Casinos Not On Gamstop
- Non Gamstop Casinos
- Casino Not On Gamstop
- Casino Not On Gamstop
- Non Gamstop Casinos UK
- Casino Sites Not On Gamstop
- Siti Non Aams
- Casino Online Non Aams
- Non Gamstop Casinos UK
- UK Casino Not On Gamstop
- Non Gamstop Casino UK
- UK Casinos Not On Gamstop
- UK Casino Not On Gamstop
- Non Gamstop Casino UK
- Non Gamstop Casinos
- Non Gamstop Casino Sites UK
- Best Non Gamstop Casinos
- Casino Sites Not On Gamstop
- Casino En Ligne Fiable
- UK Online Casinos Not On Gamstop
- Online Betting Sites UK
- Meilleur Site Casino En Ligne
- Migliori Casino Non Aams
- Best Non Gamstop Casino
- Crypto Casinos
- Casino En Ligne Belgique Liste
- Meilleur Site Casino En Ligne Belgique
- Bookmaker Non Aams
- カジノ ライブ
- онлайн казино с хорошей отдачей
- スマホ カジノ 稼ぐ
- ブック メーカー オッズ
- Top 3 Nhà Cái Uy Tín Nhất
- Trang Web Cá độ Bóng đá Của Việt Nam
- Casino En Ligne Avis
- Casino En Ligne France
- Casino En Ligne
- 꽁머니 토토
- Casino Online Non Aams
- Migliori Casino Non AAMS
- Meilleur Casino En Ligne
- Casino En Ligne France Légal
- Casino En Ligne France Légal
- Casinos En Ligne
- Mejores Casinos Online
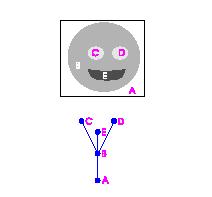 Recently, I had an opportunity to reread some of the papers on this subject. One of them has an especially simple example and I decided that this may be an appropriate place to make a comparison to
Recently, I had an opportunity to reread some of the papers on this subject. One of them has an especially simple example and I decided that this may be an appropriate place to make a comparison to 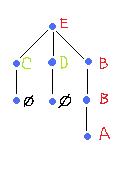 re the gray scale levels run from 0 (E) to 255 (A).
re the gray scale levels run from 0 (E) to 255 (A). Recall that
Recall that 




")


