A study came out of MIT a couple of days ago. According to the press release the study “cautions that this apparent success may be misleading because the tests being used are inadvertently stacked in favor of computers”. The image test collections such as Caltech101 make image recognition too easy by, for example, placing the object in the middle of the image.
The titles of the press releases were “Computer vision may not be as good as thought” or similar. I must ask, Who thought that computer vision was good? Who thought that testing image recognition on such a collection proves anything?
A quick look at Caltech101 reveals how extremely limited it is. In the sample images the objects are indeed centered. This means that the photographer gives the computer a hand. Also, there is virtually no background – it’s either all white or very simple, like grass behind the elephant. Now the size of the collection: 101 categories with most having about 50 images. So far this looks too easy.
Let’s look at the pictures now. It turns out that there is another problem elsewhere. The task is in fact too hard! The computer is supposed to see that the side view of a crocodile represents the same object as the front view. How? By training. Suggested number of training images: 1, 3, 5, 10, 15, 20, 30.
The idea “training” (or machine learning) is that you collect as much information about the image as possible and then let the computer sort it out by some sort of clustering. One approach is appropriately called “a bag of words” - patches in images are treated the way Google treats words in text, with no understanding of the content. You can only hope that you have captured the relevant information that will make image recognition possible. Since there is no understanding of what that relevant information is, there is no guarantee.
Then how come some researchers claim that their methods work? Good question. My guess is that by tweaking your algorithm long enough you can make it work with a small collection of images. Also, just looking at color distribution could give you enough information to “categorize” some images – in a very small collection, with very few categories.
It is well known that the digital microscope has led to an explosion of the number of images that the researcher has to deal with. On the one hand, this opens opportunities of gathering enormous amounts of data. On the other hand, tools for automatic image analysis and data management become a necessity.
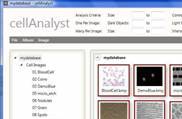
cellAnalyst is such a tool. It is intended to help the researcher to analyze his microscopy images and manage the output data.
It is especially suitable for analysis of cell images, cell counting and classification. In each image, cell cells are detected, captured, and measured. This data is presented as a table that lists all cells along with their characteristics. Each such table is recorded as an entry in a searchable database. Image processing and image management tools are also provided.
More features are planned for the future with the goal of a complete toolbox for high content analysis (HCA) and high content screening (HCS). A web based application is also under development. You can download cellAnalyst at http://cellAnalyst.net. The software comes with a complete user’s guide and a tutorial. Feedback will be appreciated.
After this formal introduction, it is interesting to observe that cellAnalyst can also be seen as a visual search engine. Indeed, the search is based entirely on the data extracted from images instead of text, tags, etc.
Santa Barbara: ocean on one side, mountains on the other, and 65 degrees! In 3 days I didn’t see a single cloud. The sky was so blue that it looked photoshopped.
The workshop was very well organized. The only problem I had was that you didn’t get a break after every talk. You need 5 minutes to digest, recharge, discuss the talk with your neighbor, or just stretch your legs.
The talks were mostly academic (zebra fish is pretty much covered). But 3-4 talks were excellently presented and very educational.
This biology stuff is complicated!
Most image analysis methods are intended for specific problems. But, in addition, each problem may have different methods eqully applicable. No-one is concerned that the results could be also different (see last post).
The Open Microscopy Environment could have a good future.
One non-academic talk was by a person from Definiens. Unfortunately only generalities were presented followed by a few examples. Secretive. A top-down approach isn’t a good idea anyway.
Dr. Pahwa and I had a few good discussions about cellAnalyst with several people. More in a couple of days.
You get 65 degrees only for a few hours in the afternoon. When you get out in the morning, it’s more like 40 or less.
The post is published here. This is the main quote:
In computer vision, no problem has been completely solved. People tend to move to more complex problems in an anxiety to do something new, but the fact is that this fatally builds upon a very wobbly foundation of partial solutions. My fear is that there is a high risk that nothing really gets done in this process.
I agree totally! Computer vision lacks a solid foundation. I think there are many reasons but the biggest one is the emphasis on different “solutions”, “methods” and “algorithms”. So, you have many solutions for the same problem, but is this situation good for the user? As a user I wouldn’t mind having several different ways to solve my problem - but only if they give the same answer!
HOW is important but WHAT is more important!
That’s why I think that the only solid foundation can be mathematics. I started the wiki to try to collect as much stuff as possible starting from the most elementary (or most fundamental if you prefer - I do) and then try to work it out so that you wouldn’t have to redo it. But it goes slowly…
Let’s consider a few optical illusions (copied from Wikipedia). They do work as advertized. Then we try to see how Pixcavator handles them (it took just a few seconds for each).
First the grid illusion. Dark spots seem to appear in the crossings.
That one is easy. Pixcavator isn’t fooled at all – there are no dark spots! There are in fact light spots - captured with green.
Next, the faces-or-vase illusion.
Pixcavator has found both the faces (dark objects) and the vase (light object), no problem.
In the Ponzo illusion, the “farther” bar appears longer than the “closer” one.
Pixcavator does not measure lengths directly but the perimeters of the bars are 170 and 176 (the computation of length is a bit tricky).
Similarly, in the Müller-Lyer illusion the middle arrow appears longer.
The perimeters according to Pixcavator are 682, 701, and 710.
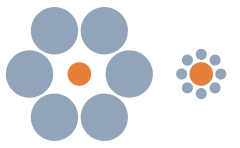
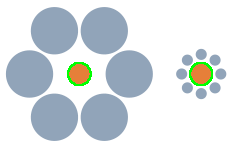
In the Ebbinghaus illusion the brown circle on the left seems smaller that the one on the right.
But the areas are 396 and 398.
The Jastrow illusion is even more extreme. The figures are clearly different!
But you can’t fool the computer: the areas are 13365 and 13362, perimeters 596 and 595.
In the “simultaneous contrast illusion”, the gray bar has the same gray level throughout.
Pixcavator does not handle this well. The reason is that it doesn’t even recognize the bar as an object - it is neither dark on light nor light on dark. So this one is a tie. Well maybe - this one deserves a separate discussion.
Via TechCrunch. Google filed a patent application “Recognizing Text In Images”. It is supposed to improve indexing of internet images and also read text in images from street views, store shelves etc. Since it is related to computer vision, I decided to take a look.
First I looked at the list of claims of the patent. Those are legal statements (a few dozen in this case) that should clearly define what is new in this invention. That’s what would be protected by the patent. The claims seem a bit strange. For example it seems that the “independent” claims (ones that don’t refer to other claims) end with “and performing optical character recognition on the enhanced image”. So, there seems to be no new OCR algorithms here…
According to some comments, the idea is that there is no “OCR platform being able to do images on the level that is suggested here”. It may indeed be about a “platform” because the claims are filled with generalities. Can you patent a “platform”? Basically you put together some well known image processing-manipulation-indexing methods plus some unspecified OCR algorithms and it works! This sounds like a “business method” patent. In fact, in spite of its apparent complexity the patent reminds me of the one-click patent. And what is the point of this patent? Is it supposed to prevent Yahoo or MS from doing the same? Are we supposed to forget that it has been done before?
ALIPR is Automatic Image Tagging and Visual Image Search. Unlike with many others uploading and, therefore, testing is possible. The last report was about a year ago. Let’s see what progress has been made.
First I tried a simple image of ten coins on dark background. These are the tags: landscape, ice, waterfall, building, historical, ocean, texture, rock, natural, marble, sky, snow, frost, man-made, indoor. For a portrait of Einstein: animal, snow, landscape, mountain, lake, cloud, building, tree, predator, wild_life, rock, natural, pattern, mineral, people. Not very encouraging.
Then I read “About us”. Turns out ALIPR “is not designed for black&white photos”. Strange idea considering that b&w images are simpler than color and if you can’t solve a simpler problem how can you expect to solve a more complex one? OK, fine. Let’s try a color image (on the right). These are the tags: texture, red, food, indoor, natural, candies, bath, kitchen, painting, fruit, people, cloth, face, female, hair_style.
At this point I got bored…
This application was supposed to learn from its users. Clearly it hasn’t learnt anything. In fact there seems to be no change at all after a whole year. In fact there are no blog posts since last January. Is it dead?
















 Then I read “About us”. Turns out ALIPR “is not designed for black&white photos”. Strange idea considering that b&w images are simpler than color and if you can’t solve a simpler problem how can you expect to solve a more complex one? OK, fine. Let’s try a color image (on the right). These are the tags: texture, red, food, indoor, natural, candies, bath, kitchen, painting, fruit, people, cloth, face, female, hair_style.
Then I read “About us”. Turns out ALIPR “is not designed for black&white photos”. Strange idea considering that b&w images are simpler than color and if you can’t solve a simpler problem how can you expect to solve a more complex one? OK, fine. Let’s try a color image (on the right). These are the tags: texture, red, food, indoor, natural, candies, bath, kitchen, painting, fruit, people, cloth, face, female, hair_style. 


")


