
Measuring vegetation coverage: an image analysis example
[edit]

Q. From these images “we want to derive the area of the board covered by plant material to serve as an index of plant density.” We would like to “develop .. a simple protocol for estimating area-covered by plant material in our digital images with Pixcavator. “
This would be hard to accomplish with images similar to these. To capture the vegetation effectively, one has to separate it from the background. Then, ideally, the latter would have to either uniformly lighter or uniformly darker than the former (see Gray scale images). The light/dark squares make the task very challenging.
Instead, one can digitally isolate the squares within each image, so that the area covered by vegetation can be estimated from a set of sub-images (i.e., individual squares) with uniform background colors:

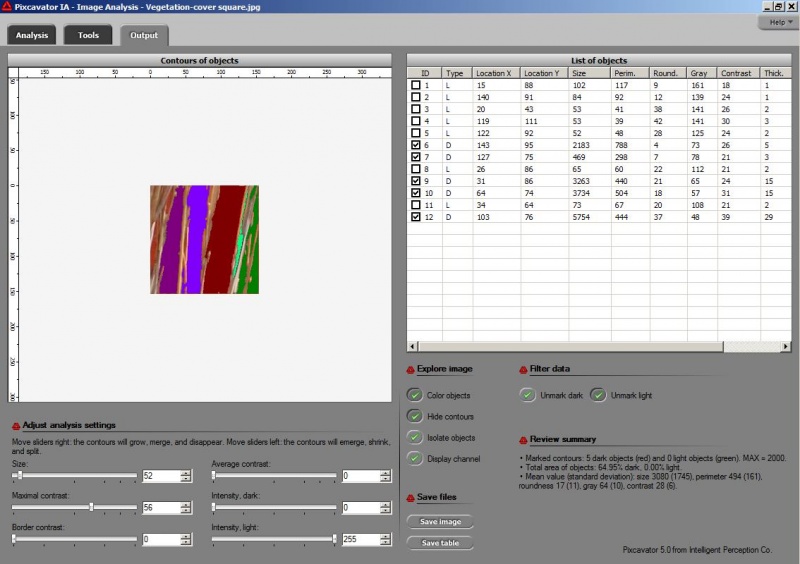
In the screenshot, the colored areas are the complement of the vegetation. Their total area is 64.95%, so the vegetation takes the rest, 35.05%.

Blue gives a good separation of the background.
More…
Digital discoveries
- Casinos Not On Gamstop
- Non Gamstop Casinos
- Casino Not On Gamstop
- Casino Not On Gamstop
- Non Gamstop Casinos UK
- Casino Sites Not On Gamstop
- Siti Non Aams
- Casino Online Non Aams
- Non Gamstop Casinos UK
- UK Casino Not On Gamstop
- Non Gamstop Casino UK
- UK Casinos Not On Gamstop
- UK Casino Not On Gamstop
- Non Gamstop Casino UK
- Non Gamstop Casinos
- Non Gamstop Casino Sites UK
- Best Non Gamstop Casinos
- Casino Sites Not On Gamstop
- Casino En Ligne Fiable
- UK Online Casinos Not On Gamstop
- Online Betting Sites UK
- Meilleur Site Casino En Ligne
- Migliori Casino Non Aams
- Best Non Gamstop Casino
- Crypto Casinos
- Casino En Ligne Belgique Liste
- Meilleur Site Casino En Ligne Belgique
- Bookmaker Non Aams
- カジノ ライブ
- онлайн казино с хорошей отдачей
- スマホ カジノ 稼ぐ
- ブック メーカー オッズ
- Top 3 Nhà Cái Uy Tín Nhất
- Trang Web Cá độ Bóng đá Của Việt Nam
- Casino En Ligne Avis
- Casino En Ligne France
- Casino En Ligne
- 꽁머니 토토
- Casino Online Non Aams
- Meilleur Casino En Ligne
Comments Off
