





Detecting melanoma, an image analysis example, part 2
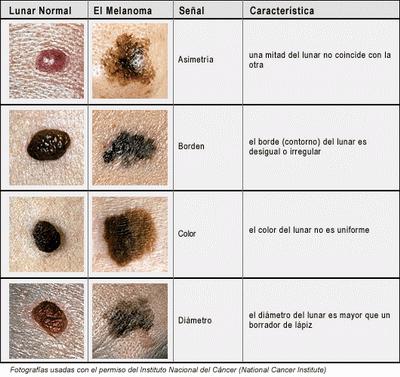
Recall the detection is based on the mnemonic ABCDE:
- Asymmetry of the spot.
- Border: irregular.
- Color: varies.
- Diameter: large.
- Evolution of the spot.
 The test for asymmetry was discussed in the last post. Suppose it is passed: the spot is symmetric more or less. Now, what about the border? To fail B, it is supposed to be irregular. Is it possible to be irregular and symmetrical at the same time? Yes, if the curve has large, but not repetitive, oscillations on one side of the axis of symmetry and then has the same oscillations on the other side. The larger are these oscillations, the less likely this is to happen however. A more likely possibility is a lot of small oscillations. In other words, we’d have to zoom in on a piece of the border and measure the smoothness of the curve. How isn’t obvious. The difficulty is that no digital curve is smooth. So, we’d have to look for oscillations that are small enough to be feasible and large enough not to be confused with edges of pixels…
The test for asymmetry was discussed in the last post. Suppose it is passed: the spot is symmetric more or less. Now, what about the border? To fail B, it is supposed to be irregular. Is it possible to be irregular and symmetrical at the same time? Yes, if the curve has large, but not repetitive, oscillations on one side of the axis of symmetry and then has the same oscillations on the other side. The larger are these oscillations, the less likely this is to happen however. A more likely possibility is a lot of small oscillations. In other words, we’d have to zoom in on a piece of the border and measure the smoothness of the curve. How isn’t obvious. The difficulty is that no digital curve is smooth. So, we’d have to look for oscillations that are small enough to be feasible and large enough not to be confused with edges of pixels…
Next is the color. Most normal moles are uniform in color. But varied shades of brown, tan, or black may be a sign of melanoma. Since all of the colors are close to each other in the spectrum, it’s possible that analysis of the gray scale would suffice. In that case the variability of color is easy to capture by computing the standard deviation.
The test for the diameter reads: a mole smaller than a pencil eraser is probably not cancerous. It is unclear whether the diameter (it fits in the mnemonic so well) is to consider here or the size/area is just as good. Either way it’s simple and reliable.
Finally, the evolution of the spot: “the change of a spot may indicate that the lesion is becoming malignant”. Not indication what kind of change that would be. The best guess is: the change of any of the other 4 characteristics.
In spite of their vagueness, these tests can be developed into image analysis procedures - with a help of medical experts. Next one would need to get from this string of numbers to a diagnosis or at least a score that reflects the likelihood of cancer. This step would also require input from a medical expert, though machine learning would be tempting too, for some…
This will be filed under Measuring objects in the wiki.
Digital discoveries
- Casinos Not On Gamstop
- Non Gamstop Casinos
- Casino Not On Gamstop
- Casino Not On Gamstop
- Non Gamstop Casinos UK
- Casino Sites Not On Gamstop
- Siti Non Aams
- Casino Online Non Aams
- Non Gamstop Casinos UK
- UK Casino Not On Gamstop
- Non Gamstop Casino UK
- UK Casinos Not On Gamstop
- UK Casino Not On Gamstop
- Non Gamstop Casino UK
- Non Gamstop Casinos
- Non Gamstop Casino Sites UK
- Best Non Gamstop Casinos
- Casino Sites Not On Gamstop
- Casino En Ligne Fiable
- UK Online Casinos Not On Gamstop
- Online Betting Sites UK
- Meilleur Site Casino En Ligne
- Migliori Casino Non Aams
- Best Non Gamstop Casino
- Crypto Casinos
- Casino En Ligne Belgique Liste
- Meilleur Site Casino En Ligne Belgique
- Bookmaker Non Aams
- カジノ ライブ
- онлайн казино с хорошей отдачей
- スマホ カジノ 稼ぐ
- ブック メーカー オッズ
- Top 3 Nhà Cái Uy Tín Nhất
- Trang Web Cá độ Bóng đá Của Việt Nam
- Casino En Ligne Avis
- Casino En Ligne France
- Casino En Ligne
- 꽁머니 토토
- Casino Online Non Aams
- Migliori Casino Non AAMS
- Meilleur Casino En Ligne
- Casino En Ligne France Légal
- Casino En Ligne France Légal
- Casinos En Ligne
- Mejores Casinos Online

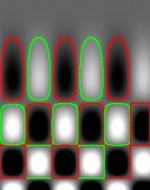
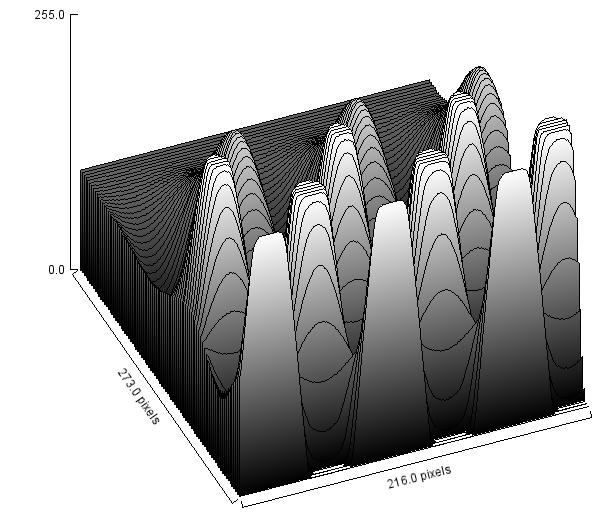 Next, we flood the valley and build dams so that we don’t allow the water to flow from one valley to another. These dams will break the image into regions each containing a single valley.
Next, we flood the valley and build dams so that we don’t allow the water to flow from one valley to another. These dams will break the image into regions each containing a single valley.








")


