This site is devoted to mathematics and its applications. Created and run by Peter Saveliev.
Filtering output data
From Intelligent Perception
The data is captured in the topology graph. However, having the topology graph isn’t enough. It provides all possible topologies in the image, but we want to pick only one. This is to be done by the user based on his criteria of what is noise: too small, low contrast, low roundness etc.
This idea is implemented in Pixcavator. In fact, Pixcavator's output table gives you a sample topology. After that you are on your own. And you have several ruler/sliders to use.
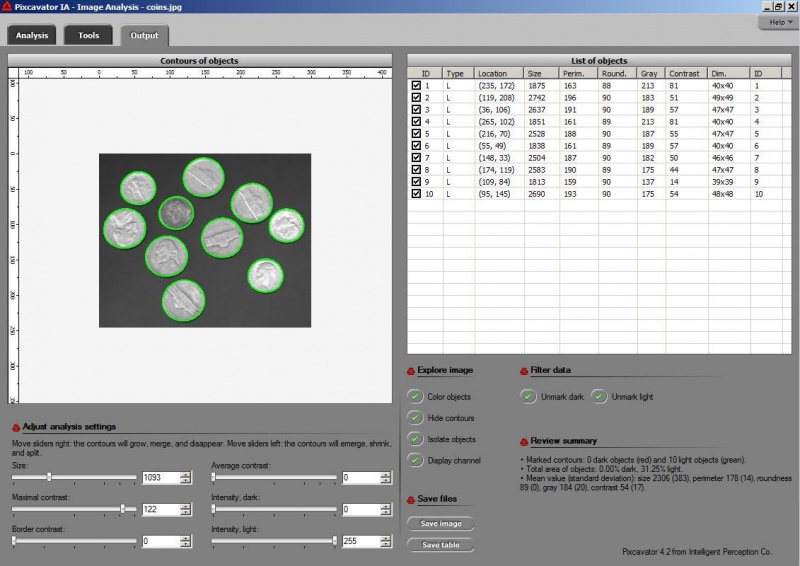
Why wouldn’t we add a second slider to the size ruler? The logic is very convincing: “the first slider removes objects from analysis that are too small - with the second slider you can exclude objects that are too large”. There are real life problems that need this kind of analysis.
What is wrong with this idea? The problem is that the idea is "binary". If the image is binary, excluding larger objects is a simple operation. We however deal with gray scale images. Sometimes objects in gray scale images look just like ones in binary images but often they have no well defined boundary (see Boundaries in gray scale images. No well defined boundary – no well defined size!
Roughly, once the bound is set, the object is allowed to grow until its size is over the bound.
Suppose the bound is 100. Then what we present as the output is objects larger than 100 BUT as close as possible to 100. If the gray level changes very gradually, the objects’ sizes end up almost exactly equal 100. If this is the case, having an upper bound (say 200) in addition to the lower bound would not change the outcome…
That’s why only a single slider for the size is present. If object A is larger than object B, A is at least as important as B. A priori, all things being equal.
The second slider is for contrast and it operates in the exact same way: the object is allowed to grow until its contrast is over the bound. The logic is the same as before: a priori, if object A has a higher contrast than object B, A is at least as important as B.
OK, but what about those real life situations when you need to exclude larger objects? That’s when you turn from image analysis to data analysis. Of course, you’d have to make sure that you have captured all objects that you care about. That’s the hard part.
The data analysis stage is the easy part. If you have captured some noise or objects that you want to exclude, that’s OK. Now you simply filter the objects on the list based on any characteristic you want. Excel has plenty of tools for that. For example, the size is too large or too small. Or the perimeter, the contrast, the roundness, the intensity. Maybe you want only the objects from 100 to 200 pixels in size. Or maybe you are only interested in the objects within 300 pixels from the center of the image (location!). All is easy at this stage.
This how the filtering of the topology graph based on thresholding would look like:
Digital discoveries
- Casinos Not On Gamstop
- Non Gamstop Casinos
- Casino Not On Gamstop
- Casino Not On Gamstop
- Non Gamstop Casinos UK
- Casino Sites Not On Gamstop
- Siti Non Aams
- Casino Online Non Aams
- Non Gamstop Casinos UK
- UK Casino Not On Gamstop
- Non Gamstop Casino UK
- UK Casinos Not On Gamstop
- UK Casino Not On Gamstop
- Non Gamstop Casino UK
- Non Gamstop Casinos
- Non Gamstop Casino Sites UK
- Best Non Gamstop Casinos
- Casino Sites Not On Gamstop
- Casino En Ligne Fiable
- UK Online Casinos Not On Gamstop
- Online Betting Sites UK
- Meilleur Site Casino En Ligne
- Migliori Casino Non Aams
- Best Non Gamstop Casino
- Crypto Casinos
- Casino En Ligne Belgique Liste
- Meilleur Site Casino En Ligne Belgique
- Bookmaker Non Aams
- カジノ ライブ
- онлайн казино с хорошей отдачей
- スマホ カジノ 稼ぐ
- ブック メーカー オッズ
- Top 3 Nhà Cái Uy Tín Nhất
- Trang Web Cá độ Bóng đá Của Việt Nam
- Casino En Ligne Avis
- Casino En Ligne France
- Casino En Ligne
- 꽁머니 토토
- Casino Online Non Aams
- Migliori Casino Non AAMS
- Meilleur Casino En Ligne
- Casino En Ligne France Légal
- Casino En Ligne France Légal
- Casinos En Ligne
- Mejores Casinos Online